Run this notebook online:![]() or Colab:
or Colab: ![]()
8.1. 序列模型¶
想象一下你正在看网飞(Netflix,一个国外的视频网站)上的电影。 作为一名忠实的用户,你对每一部电影都给出评价, 毕竟一部好电影需要更多的支持和认可。 然而事实证明,事情并不那么简单。 随着时间的推移,人们对电影的看法会发生很大的变化。 事实上,心理学家甚至对这些现象起了名字:
锚定(anchoring)效应:基于其他人的意见做出评价。 例如,奥斯卡颁奖后,受到关注的电影的评分会上升,尽管它还是原来那部电影。 这种影响将持续几个月,直到人们忘记了这部电影曾经获得的奖项。 结果表明( [Wu et al., 2017]),这种效应会使评分提高半个百分点以上。
享乐适应(hedonic adaption):人们迅速接受并且适应一种更好或者更坏的情况 作为新的常态。 例如,在看了很多好电影之后,人们会强烈期望下部电影会更好。 因此,在许多精彩的电影被看过之后,即使是一部普通的也可能被认为是糟糕的。
季节性(seasonality):少有观众喜欢在八月看圣诞老人的电影。
有时,电影会由于导演或演员在制作中的不当行为变得不受欢迎。
有些电影因为其极度糟糕只能成为小众电影。Plan9from Outer Space和Troll2就因为这个原因而臭名昭著的。
简而言之,电影评分决不是固定不变的。 因此,使用时间动力学可以得到更准确的电影推荐 [Koren, 2009]。 当然,序列数据不仅仅是关于电影评分的。 下面给出了更多的场景:
在使用应用程序时,许多用户都有很强的特定习惯。 例如,在学生放学后社交媒体应用更受欢迎。在市场开放时股市交易软件更常用。
预测明天的股价要比过去的股价更困难,尽管两者都只是估计一个数字。 毕竟,先见之明比事后诸葛亮难得多。 在统计学中,前者(对超出已知观测范围进行预测)称为外推法(extrapolation), 而后者(在现有观测值之间进行估计)称为内插法(interpolation)。
在本质上,音乐、语音、文本和视频都是连续的。 如果它们的序列被我们重排,那么就会失去原有的意义。 比如,一个文本标题“狗咬人”远没有“人咬狗”那么令人惊讶,尽管组成两句话的字完全相同。
地震具有很强的相关性,即大地震发生后,很可能会有几次小余震, 这些余震的强度比非大地震后的余震要大得多。 事实上,地震是时空相关的,即余震通常发生在很短的时间跨度和很近的距离内。
人类之间的互动也是连续的,这可以从微博上的争吵和辩论中看出。
8.1.1. 统计工具¶
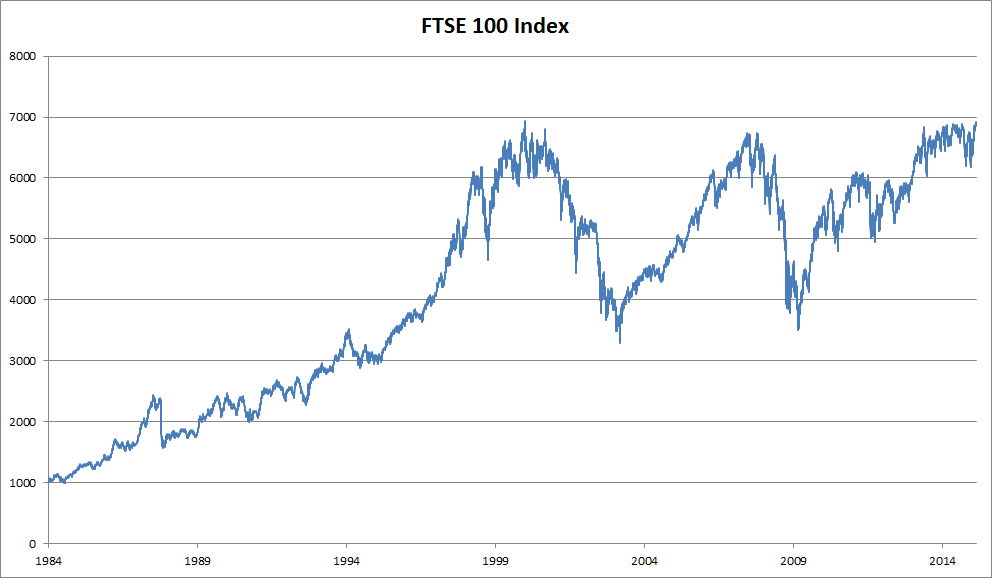
处理序列数据需要统计工具和新的深度神经网络架构。 为了简单起见,我们以
fig_ftse100所示的股票价格(富时100指数)为例。
 :width: 400px .. _fig_ftse100:
:width: 400px .. _fig_ftse100:
其中,用\(x_t\)表示价格,即在时间步(time step) \(t \in \mathbb{Z}^+\)时,观察到的价格\(x_t\)。 请注意,\(t\)对于本文中的序列通常是离散的,并在整数或其子集上变化。 假设一个交易员想在\(t\)日的股市中表现良好,于是通过以下途径预测\(x_t\):
8.1.1.1. 自回归模型¶
为了实现这个预测,交易员可以使用回归模型, 例如在 Section 3.3中训练的模型。 仅有一个主要问题:输入数据的数量, 输入\(x_{t-1}, \ldots, x_1\)本身因\(t\)而异。 也就是说,输入数据的数量这个数字将会随着我们遇到的数据量的增加而增加, 因此需要一个近似方法来使这个计算变得容易处理。 本章后面的大部分内容将围绕着如何有效估计 \(P(x_t \mid x_{t-1}, \ldots, x_1)\)展开。 简单地说,它归结为以下两种策略。
第一种策略,假设在现实情况下相当长的序列 \(x_{t-1}, \ldots, x_1\)可能是不必要的, 因此我们只需要满足某个长度为\(\tau\)的时间跨度, 即使用观测序列\(x_{t-1}, \ldots, x_{t-\tau}\)。 当下获得的最直接的好处就是参数的数量总是不变的, 至少在\(t > \tau\)时如此,这就使我们能够训练一个上面提及的深度网络。 这种模型被称为自回归模型(autoregressive models), 因为它们是对自己执行回归。
第二种策略,如 fig_sequence-model所示,
是保留一些对过去观测的总结\(h_t\),
并且同时更新预测\(\hat{x}_t\)和总结\(h_t\)。
这就产生了基于\(\hat{x}_t = P(x_t \mid h_{t})\)估计\(x_t\),
以及公式\(h_t = g(h_{t-1}, x_{t-1})\)更新的模型。
由于\(h_t\)从未被观测到,这类模型也被称为
隐变量自回归模型(latent autoregressive models)。
 .. _fig_sequence-model:
.. _fig_sequence-model:
这两种情况都有一个显而易见的问题:如何生成训练数据? 一个经典方法是使用历史观测来预测下一个未来观测。 显然,我们并不指望时间会停滞不前。 然而,一个常见的假设是虽然特定值\(x_t\)可能会改变, 但是序列本身的动力学不会改变。 这样的假设是合理的,因为新的动力学一定受新的数据影响, 而我们不可能用目前所掌握的数据来预测新的动力学。 统计学家称不变的动力学为静止的(stationary)。 因此,整个序列的估计值都将通过以下的方式获得:
注意,如果我们处理的是离散的对象(如单词), 而不是连续的数字,则上述的考虑仍然有效。 唯一的差别是,对于离散的对象, 我们需要使用分类器而不是回归模型来估计\(P(x_t \mid x_{t-1}, \ldots, x_1)\)。
8.1.1.2. 马尔可夫模型¶
回想一下,在自回归模型的近似法中, 我们使用\(x_{t-1}, \ldots, x_{t-\tau}\) 而不是\(x_{t-1}, \ldots, x_1\)来估计\(x_t\)。 只要这种是近似精确的,我们就说序列满足马尔可夫条件(Markov condition)。 特别是,如果\(\tau = 1\),得到一个 一阶马尔可夫模型(first-order Markov model), \(P(x)\)由下式给出:
当假设\(x_t\)仅是离散值时,这样的模型特别棒, 因为在这种情况下,使用动态规划可以沿着马尔可夫链精确地计算结果。 例如,我们可以高效地计算\(P(x_{t+1} \mid x_{t-1})\):
利用这一事实,我们只需要考虑过去观察中的一个非常短的历史: \(P(x_{t+1} \mid x_t, x_{t-1}) = P(x_{t+1} \mid x_t)\)。 隐马尔可夫模型中的动态规划超出了本节的范围 (我们将在 Section 9.4再次遇到), 而动态规划这些计算工具已经在控制算法和强化学习算法广泛使用。
8.1.1.3. 因果关系¶
原则上,将\(P(x_1, \ldots, x_T)\)倒序展开也没什么问题。 毕竟,基于条件概率公式,我们总是可以写出:
事实上,如果基于一个马尔可夫模型, 我们还可以得到一个反向的条件概率分布。 然而,在许多情况下,数据存在一个自然的方向,即在时间上是前进的。 很明显,未来的事件不能影响过去。 因此,如果我们改变\(x_t\),可能会影响未来发生的事情\(x_{t+1}\),但不能反过来。 也就是说,如果我们改变\(x_t\),基于过去事件得到的分布不会改变。 因此,解释\(P(x_{t+1} \mid x_t)\)应该比解释\(P(x_t \mid x_{t+1})\)更容易。 例如,在某些情况下,对于某些可加性噪声\(\epsilon\), 显然我们可以找到\(x_{t+1} = f(x_t) + \epsilon\), 而反之则不行 [Hoyer et al., 2009]。 这是个好消息,因为这个前进方向通常也是我们感兴趣的方向。 彼得斯等人写的这本书 [Peters et al., 2017] 已经解释了关于这个主题的更多内容,而我们仅仅触及了它的皮毛。
8.1.2. 训练¶
在了解了上述统计工具后,让我们在实践中尝试一下! 首先,我们生成一些数据:使用正弦函数和一些可加性噪声来生成序列数据, 时间步为\(1, 2, \ldots, 1000\)。
%load ../utils/djl-imports
%load ../utils/plot-utils
%load ../utils/Functions.java
NDManager manager = NDManager.newBaseManager();
public static Figure plot(double[] x, double[] y, String xLabel, String yLabel) {
ScatterTrace trace = ScatterTrace.builder(x,y)
.mode(ScatterTrace.Mode.LINE)
.build();
Layout layout = Layout.builder()
.showLegend(true)
.xAxis(Axis.builder().title(xLabel).build())
.yAxis(Axis.builder().title(yLabel).build())
.build();
return new Figure(layout, trace);
}
int T = 1000; // 总共生成1000个点
NDArray time = manager.arange(1f, T+1);
NDArray x = time.mul(0.01).sin().add(
manager.randomNormal(0f, 0.2f, new Shape(T), DataType.FLOAT32));
double[] xAxis = Functions.floatToDoubleArray(time.toFloatArray());
double[] yAxis = Functions.floatToDoubleArray(x.toFloatArray());
plot(xAxis, yAxis, "time", "x");
接下来,我们需要将这样一个序列转换为我们的模型可以训练的特征和标签。 基于嵌入维度 \(\tau\) ,我们将数据映射到 \(y_t = x_t\) 和\(\mathbf{x}_t = [x_{t-\tau}, \ldots, x_{t-1}]\) 对中。 精明的读者可能已经注意到,这给我们提供了 \(\tau\) 更少的数据示例,因为我们没有足够的第一个 \(\tau\) 的历史记录。 一个简单的修复,特别是如果序列很长, 就是放弃这几个术语。 或者我们可以用零填充序列。 这里,我们仅使用前600个特征标签对进行训练。
int tau = 4;
NDArray features = manager.zeros(new Shape(T - tau, tau));
for (int i = 0; i < tau; i++) {
features.set(new NDIndex(":, {}", i), x.get(new NDIndex("{}:{}", i, T - tau + i)));
}
NDArray labels = x.get(new NDIndex("" + tau + ":")).reshape(new Shape(-1,1));
int batchSize = 16;
int nTrain = 600;
// 只有第一个“nTrain”示例用于训练
ArrayDataset trainIter = new ArrayDataset.Builder()
.setData(features.get(new NDIndex(":{}", nTrain)))
.optLabels(labels.get(new NDIndex(":{}", nTrain)))
.setSampling(batchSize, true)
.build();
在这里,我们使体系结构相当简单: 只有两个完全连接层的MLP,ReLU激活和平方损耗。
// 一个简单的MLP
public static SequentialBlock getNet() {
SequentialBlock net = new SequentialBlock();
net.add(Linear.builder().setUnits(10).build());
net.add(Activation::relu);
net.add(Linear.builder().setUnits(1).build());
return net;
}
现在我们已经准备好训练模型了。下面的代码与前面章节中的培训循环基本相同, 例如 Section 3.3. 因此,我们将不深入探讨太多细节。
// 我们在函数 "train" 之外添加此项,以便在笔记本中保留对训练对象的强引用(否则有时可能会关闭)
Trainer trainer = null;
public static Model train(SequentialBlock net, ArrayDataset dataset, int batchSize, int numEpochs, float learningRate)
throws IOException, TranslateException {
// 平方误差
Loss loss = Loss.l2Loss();
Tracker lrt = Tracker.fixed(learningRate);
Optimizer adam = Optimizer.adam().optLearningRateTracker(lrt).build();
DefaultTrainingConfig config = new DefaultTrainingConfig(loss)
.optOptimizer(adam) // 优化器(损失函数)
.optInitializer(new XavierInitializer(), "")
.addTrainingListeners(TrainingListener.Defaults.logging()); // 日志
Model model = Model.newInstance("sequence");
model.setBlock(net);
trainer = model.newTrainer(config);
for (int epoch = 1; epoch <= numEpochs; epoch++) {
// 在数据集上迭代
for (Batch batch : trainer.iterateDataset(dataset)) {
// 更新损失率和评估器
EasyTrain.trainBatch(trainer, batch);
// 更新参数
trainer.step();
batch.close();
}
// 在新epoch结束时重置训练和验证求值器
trainer.notifyListeners(listener -> listener.onEpoch(trainer));
System.out.printf("Epoch %d\n", epoch);
System.out.printf("Loss %f\n", trainer.getTrainingResult().getTrainLoss());
}
return model;
}
SequentialBlock net = getNet();
Model model = train(net, trainIter, batchSize, 5, 0.01f);
INFO Training on: 4 GPUs.
INFO Load MXNet Engine Version 1.9.0 in 0.064 ms.
Training: 100% |████████████████████████████████████████|
INFO Epoch 1 finished.
Epoch 1
Loss 0.048920
Training: 100% |████████████████████████████████████████|
INFO Epoch 2 finished.
Epoch 2
Loss 0.029020
Training: 100% |████████████████████████████████████████|
INFO Epoch 3 finished.
Epoch 3
Loss 0.026346
Training: 100% |████████████████████████████████████████|
INFO Epoch 4 finished.
Epoch 4
Loss 0.024183
Training: 100% |████████████████████████████████████████|
INFO Epoch 5 finished.
Epoch 5
Loss 0.024385
8.1.3. 预测¶
由于训练损失很小,我们希望我们的模型能够很好地工作。 让我们看看这在实践中意味着什么。 首先要检查的是模型能够预测下一个时间步发生的情况, 即提前一步预测。
Translator translator = new NoopTranslator(null);
Predictor predictor = model.newPredictor(translator);
NDArray onestepPreds = ((NDList) predictor.predict(new NDList(features))).get(0);
ScatterTrace trace = ScatterTrace.builder(Functions.floatToDoubleArray(time.toFloatArray()),
Functions.floatToDoubleArray(x.toFloatArray()))
.mode(ScatterTrace.Mode.LINE)
.name("data")
.build();
ScatterTrace trace2 = ScatterTrace.builder(Functions.floatToDoubleArray(time.get(new NDIndex("{}:", tau)).toFloatArray()),
Functions.floatToDoubleArray(onestepPreds.toFloatArray()))
.mode(ScatterTrace.Mode.LINE)
.name("1-step preds")
.build();
Layout layout = Layout.builder()
.showLegend(true)
.xAxis(Axis.builder().title("time").build())
.yAxis(Axis.builder().title("x").build())
.build();
new Figure(layout, trace, trace2);
正如我们预期的那样,提前一步的预测看起来不错。
即使超过604次(n_train+tau)观测,这些预测看起来仍然可信。
然而,这里只有一个小问题:
如果我们只在时间步604之前观察序列数据,我们就不可能希望收到所有未来一步预测的输入。
相反,我们需要一步一步地向前迈进:
通常,对于高达 \(x_t\) 的观测序列,其在时间步长 \(t+k\) 处的预测输出 \(\hat{x}_{t+k}\) 称为:math:`k`-步进预测。 由于我们观察到高达 \(x_{604}\),其 \(k\)-步骤-预测为 \(\hat{x}_{604+k}\)。 换句话说,我们将不得不使用我们自己的预测来进行多步预测。 让我们看看进展如何。
NDArray multiStepPreds = manager.zeros(new Shape(T));
multiStepPreds.set(new NDIndex(":{}", nTrain + tau), x.get(new NDIndex(":{}", nTrain + tau)));
for (int i = nTrain + tau; i < T; i++) {
NDArray tempX = multiStepPreds.get(new NDIndex("{}:{}", i - tau, i)).reshape(new Shape(1, -1));
NDArray prediction = ((NDList) predictor.predict(new NDList(tempX))).get(0);
multiStepPreds.set(new NDIndex(i), prediction);
}
ScatterTrace trace = ScatterTrace.builder(Functions.floatToDoubleArray(time.toFloatArray()),
Functions.floatToDoubleArray(x.toFloatArray()))
.mode(ScatterTrace.Mode.LINE)
.name("data")
.build();
ScatterTrace trace2 = ScatterTrace.builder(Functions.floatToDoubleArray(time.get(new NDIndex("{}:", tau)).toFloatArray()),
Functions.floatToDoubleArray(onestepPreds.toFloatArray()))
.mode(ScatterTrace.Mode.LINE)
.name("1-step preds")
.build();
ScatterTrace trace3 = ScatterTrace.builder(Functions.floatToDoubleArray(time.get(
new NDIndex("{}:", nTrain + tau)).toFloatArray()),
Functions.floatToDoubleArray(multiStepPreds.get(
new NDIndex("{}:", nTrain + tau)).toFloatArray()))
.mode(ScatterTrace.Mode.LINE)
.name("multistep preds")
.build();
Layout layout = Layout.builder()
.showLegend(true)
.xAxis(Axis.builder().title("time").build())
.yAxis(Axis.builder().title("x").build())
.build();
new Figure(layout, trace, trace2, trace3);
正如上面的例子所示,这是一个惊人的失败。经过几个预测步骤后,预测很快衰减为常数。 为什么算法工作得这么差? 这最终是由于错误累积的事实。 假设在第1步之后,出现了一些错误 \(\epsilon_1 = \bar\epsilon\)。 现在,步骤2的输入被 \(\epsilon_1\) 扰动,因此对于某些常量 \(c\) , 我们会遇到一些顺序为 \(\epsilon_2 = \bar\epsilon + c \epsilon_1\) 的错误,依此类推。 误差可能很快偏离真实观测值。 这是一种普遍现象。 例如,未来24小时的天气预报往往相当准确,但除此之外,准确度会迅速下降。 我们将在本章及以后讨论改进方法。
让我们仔细看看 \(k\)-超前 预测中的困难 通过计算对 \(k = 1, 4, 16, 64\) 的整个序列的预测。
int maxSteps = 64;
NDArray features = manager.zeros(new Shape(T - tau - maxSteps + 1, tau + maxSteps));
// 列 `i` (`i` < `tau`) 是从 `x` 观察到的来自
// `i + 1` 到 `i + T - tau - maxSteps + 1`
for (int i = 0; i < tau; i++) {
features.set(new NDIndex(":, {}", i), x.get(new NDIndex("{}:{}", i, i + T - tau - maxSteps + 1)));
}
// 列 `i` (`i` >= `tau`) 是 (`i - tau + 1`) 的超前预测
// 从 `i + 1` to `i + T - tau - maxSteps + 1` 的时间步长
for (int i = tau; i < tau + maxSteps; i++) {
NDArray tempX = features.get(new NDIndex(":, {}:{}", i - tau, i));
NDArray prediction = ((NDList) predictor.predict(new NDList(tempX))).get(0);
features.set(new NDIndex(":, {}", i), prediction.reshape(-1));
}
int[] steps = new int[] {1, 4, 16, 64};
ScatterTrace[] traces = new ScatterTrace[4];
for (int i = 0; i < traces.length; i++) {
int step = steps[i];
traces[i] = ScatterTrace.builder(Functions.floatToDoubleArray(time.get(new NDIndex("{}:{}", tau + step - 1, T - maxSteps + i)).toFloatArray()),
Functions.floatToDoubleArray(features.get(
new NDIndex(":,{}", tau + step - 1)).toFloatArray())
)
.mode(ScatterTrace.Mode.LINE)
.name(step + "-step preds")
.build();
}
Layout layout = Layout.builder()
.showLegend(true)
.xAxis(Axis.builder().title("time").build())
.yAxis(Axis.builder().title("x").build())
.build();
new Figure(layout, traces);
这清楚地说明了当我们试图预测未来时,预测的质量是如何变化的。 尽管提前4步的预测看起来仍然不错,但超出这一步的任何预测几乎都是无用的。
8.1.4. 总结¶
内插法和外推法在难度上有很大差别。因此,如果您有一个序列,那么在进行训练时,请始终遵守数据的时间顺序,即永远不要对未来的数据进行训练。
序列模型需要专门的统计工具进行估计。两种流行的选择是自回归模型和潜变量自回归模型。
对于因果模型(例如,时间向前),估计正向通常比反向容易得多。
对于时间步 \(t\) 之前的观测序列,其在时间步 \(t+k\) 的预测输出为 \(k\)-超前预测。当我们通过增加 \(k\) 来进一步预测时,误差会累积,预测质量会下降,通常会急剧下降。
8.1.5. 练习¶
在本部分的实验中对模型进行了改进。
纳入超过过去4次的观察结果?你到底需要多少?
如果没有noise,您需要多少过去的观察?提示:您可以将 \(\sin\) 和 \(\cos\) 写成微分方程。
在保持特征总数不变的情况下,您能否合并旧的观察结果?这会提高准确性吗?为什么?
改变神经网络结构并评估性能。
投资者希望找到一种好的证券来购买。他查看过去的回报,以决定哪一个可能表现良好。这种策略可能会出什么问题?
因果关系是否也适用于文本?到什么程度?
举例说明何时可能需要潜在自回归模型来捕获数据的动态。