Run this notebook online:![]() or Colab:
or Colab: ![]()
13.2. Anchor Boxes¶
Object detection algorithms usually sample a large number of regions in the input image, determine whether these regions contain objects of interest, and adjust the edges of the regions so as to predict the ground-truth bounding box of the target more accurately. Different models may use different region sampling methods. Here, we introduce one such method: it generates multiple bounding boxes with different sizes and aspect ratios while centering on each pixel. These bounding boxes are called anchor boxes. We will practice object detection based on anchor boxes in the following sections.
%load ../utils/djl-imports
%load ../utils/ImageUtils.java
13.2.1. Generating Multiple Anchor Boxes¶
Assume that the input image has a height of \(h\) and width of \(w\). We generate anchor boxes with different shapes centered on each pixel of the image. Assume the size is \(s\in (0, 1]\), the aspect ratio is \(r > 0\), and the width and height of the anchor box are \(ws\sqrt{r}\) and \(hs/\sqrt{r}\), respectively. When the center position is given, an anchor box with known width and height is determined.
Below we set a set of sizes \(s_1,\ldots, s_n\) and a set of aspect ratios \(r_1,\ldots, r_m\). If we use a combination of all sizes and aspect ratios with each pixel as the center, the input image will have a total of \(whnm\) anchor boxes. Although these anchor boxes may cover all ground-truth bounding boxes, the computational complexity is often excessive. Therefore, we are usually only interested in a combination containing \(s_1\) or \(r_1\) sizes and aspect ratios, that is:
That is, the number of anchor boxes centered on the same pixel is \(n+m-1\). For the entire input image, we will generate a total of \(wh(n+m-1)\) anchor boxes.
The above method of generating anchor boxes has been implemented in the
MultiBoxPrior class. We specify the input, a set of sizes, and a set
of aspect ratios, and this function will return all the anchor boxes
entered.
NDManager manager = NDManager.newBaseManager();
Image img = ImageFactory.getInstance()
.fromUrl("https://raw.githubusercontent.com/d2l-ai/d2l-en/master/img/catdog.jpg");
// Width and Height of catdog.jpg
int WIDTH = img.getWidth();
int HEIGHT = img.getHeight();
System.out.println(WIDTH);
System.out.println(HEIGHT);
List<Float> sizes = Arrays.asList(0.75f, 0.5f, 0.25f);
List<Float> ratios = Arrays.asList(1f, 2f, 0.5f);
MultiBoxPrior mbp = MultiBoxPrior.builder().setSizes(sizes).setRatios(ratios).build();
NDArray X = manager.randomUniform(0, 1, new Shape(1, 3, HEIGHT, WIDTH));
NDArray Y = mbp.generateAnchorBoxes(X);
Y.getShape();
728
561
(1, 2042040, 4)
We can see that the shape of the returned anchor box variable y is
(batch size, number of anchor boxes, 4). After changing the shape of the
anchor box variable y to (image height, image width, number of
anchor boxes centered on the same pixel, 4), we can obtain all the
anchor boxes centered on a specified pixel position. In the following
example, we access the first anchor box centered on (250, 250). It has
four elements: the \(x, y\) axis coordinates in the upper-left
corner and the \(x, y\) axis coordinates in the lower-right corner
of the anchor box. The coordinate values of the \(x\) and \(y\)
axis are divided by the width and height of the image, respectively, so
the value range is between 0 and 1.
NDArray boxes = Y.reshape(HEIGHT, WIDTH, 5, 4);
boxes.get(250, 250, 0);
ND: (4) gpu(0) float32
[0.0551, 0.0715, 0.6331, 0.8215]
In order to describe all anchor boxes centered on one pixel in the
image, we first define the drawBBoxes() function to draw multiple
bounding boxes on the image. This uses the in-built
drawBoundingBoxes() function from the Image class which takes in
a DetectedObjects object and draws them on the original image.
/*
* Draw Bounding Boxes on Image
*
* Saved in ImageUtils
*/
public static void drawBBoxes(Image img, NDArray boxes, String[] labels) {
if (labels == null) {
labels = new String[(int) boxes.size(0)];
Arrays.fill(labels, "");
}
List<String> classNames = new ArrayList();
List<Double> prob = new ArrayList();
List<BoundingBox> boundBoxes = new ArrayList();
for (int i = 0; i < boxes.size(0); i++) {
NDArray box = boxes.get(i);
Rectangle rect = ImageUtils.bboxToRect(box);
classNames.add(labels[i]);
prob.add(1.0);
boundBoxes.add(rect);
}
DetectedObjects detectedObjects = new DetectedObjects(classNames, prob, boundBoxes);
img.drawBoundingBoxes(detectedObjects);
}
As we just saw, the coordinate values of the \(x\) and \(y\)
axis in the variable boxes have been divided by the width and height
of the image, respectively. The image function drawBoundingBoxes()
automatically restores the original coordinate values of the anchor
boxes. Since drawBoundingBoxes() draws on the image itself, we can
use the Image function duplicate() to create a copy of the image
and preserve the original image. Now, we can draw all the anchor boxes
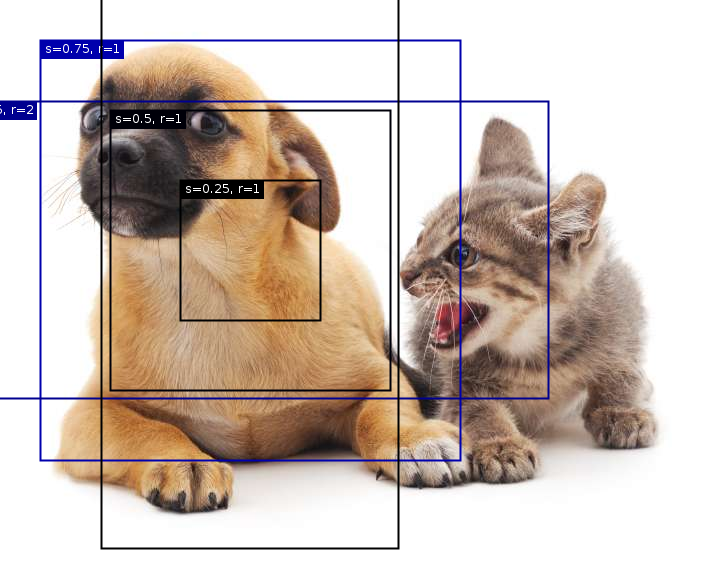
centered on (250, 250) in the image. As you can see, the blue anchor box
with a size of 0.75 and an aspect ratio of 1 covers the dog in the image
well.
Image img2 = img.duplicate();
drawBBoxes(img2, boxes.get(250, 250),
new String[]{"s=0.75, r=1", "s=0.5, r=1", "s=0.25, r=1", "s=0.75, r=2", "s=0.75, r=0.5"});
img2.getWrappedImage()
13.2.2. Intersection over Union¶
We just mentioned that the anchor box covers the dog in the image well. If the ground-truth bounding box of the target is known, how can “well” here be quantified? An intuitive method is to measure the similarity between anchor boxes and the ground-truth bounding box. We know that the Jaccard index can measure the similarity between two sets. Given sets \(\mathcal{A}\) and \(\mathcal{B}\), their Jaccard index is the size of their intersection divided by the size of their union:
In fact, we can consider the pixel area of a bounding box as a
collection of pixels. In this way, we can measure the similarity of the
two bounding boxes by the Jaccard index of their pixel sets. When we
measure the similarity of two bounding boxes, we usually refer the
Jaccard index as intersection over union (IoU), which is the ratio of
the intersecting area to the union area of the two bounding boxes, as
shown in fig_iou. The value range of IoU is between 0 and 1:
0 means that there are no overlapping pixels between the two bounding
boxes, while 1 indicates that the two bounding boxes are equal.
 .. _fig_iou:
.. _fig_iou:
For the remainder of this section, we will use IoU to measure the similarity between anchor boxes and ground-truth bounding boxes, and between different anchor boxes.
13.2.3. Labeling Training Set Anchor Boxes¶
In the training set, we consider each anchor box as a training example. In order to train the object detection model, we need to mark two types of labels for each anchor box: first, the category of the target contained in the anchor box (category) and, second, the offset of the ground-truth bounding box relative to the anchor box (offset). In object detection, we first generate multiple anchor boxes, predict the categories and offsets for each anchor box, adjust the anchor box position according to the predicted offset to obtain the bounding boxes to be used for prediction, and finally filter out the prediction bounding boxes that need to be output.
We know that, in the object detection training set, each image is labelled with the location of the ground-truth bounding box and the category of the target contained. After the anchor boxes are generated, we primarily label anchor boxes based on the location and category information of the ground-truth bounding boxes similar to the anchor boxes. So how do we assign ground-truth bounding boxes to anchor boxes similar to them?
Assume that the anchor boxes in the image are \(A_1, A_2, \ldots, A_{n_a}\) and the ground-truth bounding boxes are \(B_1, B_2, \ldots, B_{n_b}\) and \(n_a \geq n_b\). Define matrix \(\mathbf{X} \in \mathbb{R}^{n_a \times n_b}\), where element \(x_{ij}\) in the \(i^\mathrm{th}\) row and \(j^\mathrm{th}\) column is the IoU of the anchor box \(A_i\) to the ground-truth bounding box \(B_j\). First, we find the largest element in the matrix \(\mathbf{X}\) and record the row index and column index of the element as \(i_1,j_1\). We assign the ground-truth bounding box \(B_{j_1}\) to the anchor box \(A_{i_1}\). Obviously, anchor box \(A_{i_1}\) and ground-truth bounding box \(B_{j_1}\) have the highest similarity among all the “anchor box–ground-truth bounding box” pairings. Next, discard all elements in the \(i_1\)th row and the \(j_1\)th column in the matrix \(\mathbf{X}\). Find the largest remaining element in the matrix \(\mathbf{X}\) and record the row index and column index of the element as \(i_2,j_2\). We assign ground-truth bounding box \(B_{j_2}\) to anchor box \(A_{i_2}\) and then discard all elements in the \(i_2\)th row and the \(j_2\)th column in the matrix \(\mathbf{X}\). At this point, elements in two rows and two columns in the matrix \(\mathbf{X}\) have been discarded.
We proceed until all elements in the \(n_b\) column in the matrix \(\mathbf{X}\) are discarded. At this time, we have assigned a ground-truth bounding box to each of the \(n_b\) anchor boxes. Next, we only traverse the remaining \(n_a - n_b\) anchor boxes. Given anchor box \(A_i\), find the bounding box \(B_j\) with the largest IoU with \(A_i\) according to the \(i^\mathrm{th}\) row of the matrix \(\mathbf{X}\), and only assign ground-truth bounding box \(B_j\) to anchor box \(A_i\) when the IoU is greater than the predetermined threshold.
As shown in Section 13.2.3 (left), assuming that the maximum value in the matrix \(\mathbf{X}\) is \(x_{23}\), we will assign ground-truth bounding box \(B_3\) to anchor box \(A_2\). Then, we discard all the elements in row 2 and column 3 of the matrix, find the largest element \(x_{71}\) of the remaining shaded area, and assign ground-truth bounding box \(B_1\) to anchor box \(A_7\). Then, as shown in Section 13.2.3 (middle), discard all the elements in row 7 and column 1 of the matrix, find the largest element \(x_{54}\) of the remaining shaded area, and assign ground-truth bounding box \(B_4\) to anchor box \(A_5\). Finally, as shown in Section 13.2.3 (right), discard all the elements in row 5 and column 4 of the matrix, find the largest element \(x_{92}\) of the remaining shaded area, and assign ground-truth bounding box \(B_2\) to anchor box \(A_9\). After that, we only need to traverse the remaining anchor boxes of \(A_1, A_3, A_4, A_6, A_8\) and determine whether to assign ground-truth bounding boxes to the remaining anchor boxes according to the threshold.

Now we can label the categories and offsets of the anchor boxes. If an anchor box \(A\) is assigned ground-truth bounding box \(B\), the category of the anchor box \(A\) is set to the category of \(B\). And the offset of the anchor box \(A\) is set according to the relative position of the central coordinates of \(B\) and \(A\) and the relative sizes of the two boxes. Because the positions and sizes of various boxes in the dataset may vary, these relative positions and relative sizes usually require some special transformations to make the offset distribution more uniform and easier to fit. Assume the center coordinates of anchor box \(A\) and its assigned ground-truth bounding box \(B\) are \((x_a, y_a), (x_b, y_b)\), the widths of \(A\) and \(B\) are \(w_a, w_b\), and their heights are \(h_a, h_b\), respectively. In this case, a common technique is to label the offset of \(A\) as
The default values of the constant are \(\mu_x = \mu_y = \mu_w = \mu_h = 0, \sigma_x=\sigma_y=0.1, and \sigma_w=\sigma_h=0.2\). If an anchor box is not assigned a ground-truth bounding box, we only need to set the category of the anchor box to background. Anchor boxes whose category is background are often referred to as negative anchor boxes, and the rest are referred to as positive anchor boxes.
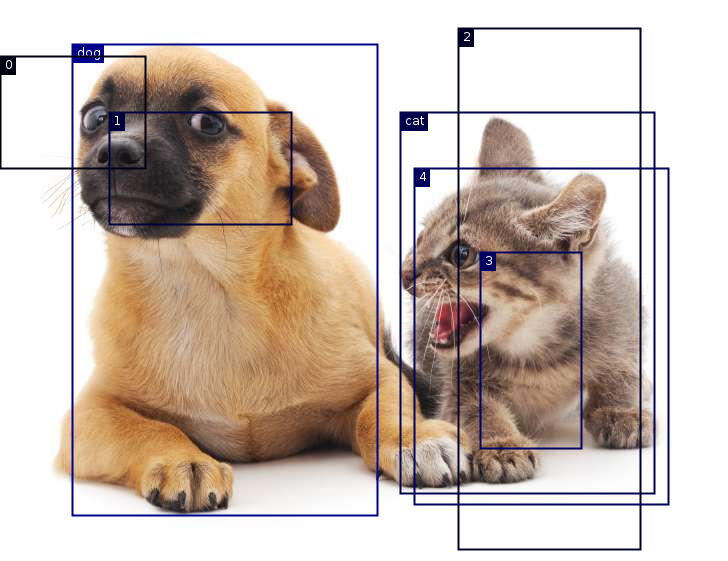
Below we demonstrate a detailed example. We define ground-truth bounding boxes for the cat and dog in the read image, where the first element is category (0 for dog, 1 for cat) and the remaining four elements are the \(x, y\) axis coordinates at top-left corner and \(x, y\) axis coordinates at lower-right corner (the value range is between 0 and 1). Here, we construct five anchor boxes to be labeled by the coordinates of the upper-left corner and the lower-right corner, which are recorded as \(A_0, \ldots, A_4\), respectively (the index in the program starts from 0). First, draw the positions of these anchor boxes and the ground-truth bounding boxes in the image.
NDArray groundTruth = manager.create(new float[][]{{0, 0.1f, 0.08f, 0.52f, 0.92f},
{1, 0.55f, 0.2f, 0.9f, 0.88f}});
NDArray anchors = manager.create(new float[][]{{0, 0.1f, 0.2f, 0.3f}, {0.15f, 0.2f, 0.4f, 0.4f},
{0.63f, 0.05f, 0.88f, 0.98f}, {0.66f, 0.45f, 0.8f, 0.8f},
{0.57f, 0.3f, 0.92f, 0.9f}});
Image img3 = img.duplicate();
drawBBoxes(img3, groundTruth.get(new NDIndex(":, 1:")), new String[]{"dog", "cat"});
drawBBoxes(img3, anchors, new String[]{"0", "1", "2", "3", "4"});
img3.getWrappedImage()
We can label categories and offsets for anchor boxes by using the
MultiBoxTarget class. This function sets the background category to
0 and increments the integer index of the target category from zero by 1
(1 for dog and 2 for cat). We add example dimensions to the anchor boxes
and ground-truth bounding boxes and construct random predicted results
with a shape of (batch size, number of categories including background,
number of anchor boxes) by using the expandDims() function.
MultiBoxTarget mbt = MultiBoxTarget.builder().build();
NDList labels = mbt.target(new NDList(anchors.expandDims(0),
groundTruth.expandDims(0),
manager.zeros(new Shape(1, 3, 5))));
There are three items in the returned result, all of which are in the tensor format. The third item is represented by the category labeled for the anchor box.
labels.get(2);
ND: (1, 5) gpu(0) float32
[[0., 1., 2., 0., 2.],
]
We analyze these labelled categories based on positions of anchor boxes and ground-truth bounding boxes in the image. First, in all “anchor box–ground-truth bounding box” pairs, the IoU of anchor box \(A_4\) to the ground-truth bounding box of the cat is the largest, so the category of anchor box \(A_4\) is labeled as cat. Without considering anchor box \(A_4\) or the ground-truth bounding box of the cat, in the remaining “anchor box–ground-truth bounding box” pairs, the pair with the largest IoU is anchor box \(A_1\) and the ground-truth bounding box of the dog, so the category of anchor box \(A_1\) is labeled as dog. Next, traverse the remaining three unlabeled anchor boxes. The category of the ground-truth bounding box with the largest IoU with anchor box \(A_0\) is dog, but the IoU is smaller than the threshold (the default is 0.5), so the category is labeled as background; the category of the ground-truth bounding box with the largest IoU with anchor box \(A_2\) is cat and the IoU is greater than the threshold, so the category is labeled as cat; the category of the ground-truth bounding box with the largest IoU with anchor box \(A_3\) is cat, but the IoU is smaller than the threshold, so the category is labeled as background.
The second item of the return value is a mask variable, with the shape of (batch size, four times the number of anchor boxes). The elements in the mask variable correspond one-to-one with the four offset values of each anchor box. Because we do not care about background detection, offsets of the negative class should not affect the target function. By multiplying by element, the 0 in the mask variable can filter out negative class offsets before calculating target function.
labels.get(1);
ND: (1, 20) gpu(0) float32
[[0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 1., 1., 1., 1.],
]
The first item returned is the four offset values labeled for each anchor box, with the offsets of negative class anchor boxes labeled as 0.
labels.get(0);
ND: (1, 20) gpu(0) float32
[[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 1.39999986e+00, 9.99999905e+00, 2.59396887e+00, 7.17542267e+00, -1.19999886e+00, 2.68817574e-01, 1.68236065e+00, -1.56545877e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, -5.71427941e-01, -1.00000012e+00, -8.94069728e-07, 6.25816226e-01],
]
13.2.4. Bounding Boxes for Prediction¶
During model prediction phase, we first generate multiple anchor boxes for the image and then predict categories and offsets for these anchor boxes one by one. Then, we obtain prediction bounding boxes based on anchor boxes and their predicted offsets. When there are many anchor boxes, many similar prediction bounding boxes may be output for the same target. To simplify the results, we can remove similar prediction bounding boxes. A commonly used method is called non-maximum suppression (NMS).
Let us take a look at how NMS works. For a prediction bounding box \(B\), the model calculates the predicted probability for each category. Assume the largest predicted probability is \(p\), the category corresponding to this probability is the predicted category of \(B\). We also refer to \(p\) as the confidence level of prediction bounding box \(B\). On the same image, we sort the prediction bounding boxes with predicted categories other than background by confidence level from high to low, and obtain the list \(L\). Select the prediction bounding box \(B_1\) with highest confidence level from \(L\) as a baseline and remove all non-benchmark prediction bounding boxes with an IoU with \(B_1\) greater than a certain threshold from \(L\). The threshold here is a preset hyperparameter. At this point, \(L\) retains the prediction bounding box with the highest confidence level and removes other prediction bounding boxes similar to it. Next, select the prediction bounding box \(B_2\) with the second highest confidence level from \(L\) as a baseline, and remove all non-benchmark prediction bounding boxes with an IoU with \(B_2\) greater than a certain threshold from \(L\). Repeat this process until all prediction bounding boxes in \(L\) have been used as a baseline. At this time, the IoU of any pair of prediction bounding boxes in \(L\) is less than the threshold. Finally, output all prediction bounding boxes in the list \(L\).
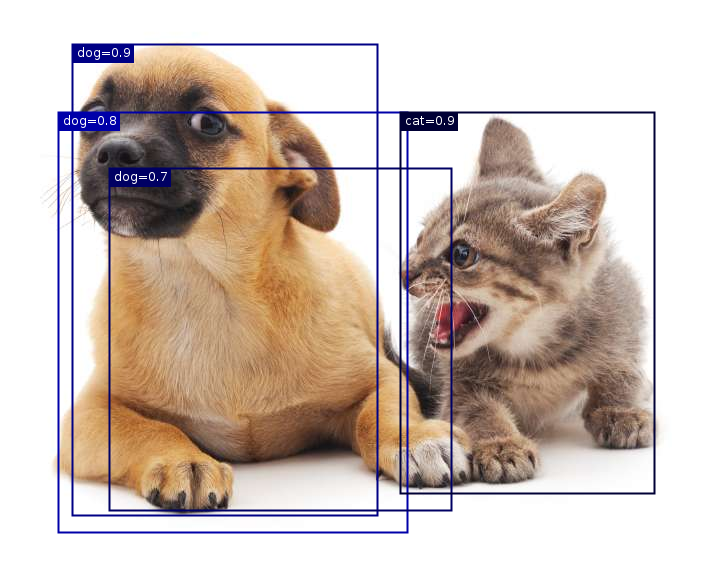
Next, we will look at a detailed example. First, construct four anchor boxes. For the sake of simplicity, we assume that predicted offsets are all 0. This means that the prediction bounding boxes are anchor boxes. Finally, we construct a predicted probability for each category.
NDArray anchors = manager.create(new float[][]{{0.1f, 0.08f, 0.52f, 0.92f}, {0.08f, 0.2f, 0.56f, 0.95f},
{0.15f, 0.3f, 0.62f, 0.91f}, {0.55f, 0.2f, 0.9f, 0.88f}});
NDArray offsetPreds = manager.zeros(new Shape(16));
NDArray clsProbs = manager.create(new float[][]{{0, 0, 0, 0}, // Predicted Probability for Background
{0.9f, 0.8f, 0.7f, 0.1f}, // Predicted Probability for Dog
{0.1f, 0.2f, 0.3f, 0.9f}}); // Predicted Probability for Cat
Draw the prediction bounding boxes and their confidence levels on the image.
Image img4 = img.duplicate();
drawBBoxes(img4, anchors, new String[]{"dog=0.9", "dog=0.8", "dog=0.7", "cat=0.9"});
img4.getWrappedImage()
We use the MultiBoxDetection class to perform NMS and set the
threshold to 0.5. This adds an example dimension to the tensor input. We
can see that the shape of the returned result is (batch size, number of
anchor boxes, 6). The 6 elements of each row represent the output
information for the same prediction bounding box. The first element is
the predicted category index, which starts from 0 (0 is dog, 1 is cat).
The value -1 indicates background or removal in NMS. The second element
is the confidence level of prediction bounding box. The remaining four
elements are the \(x, y\) axis coordinates of the upper-left corner
and the \(x, y\) axis coordinates of the lower-right corner of the
prediction bounding box (the value range is between 0 and 1).
MultiBoxDetection mbd = MultiBoxDetection.builder().optThreshold(0.5f).build();
NDArray output = mbd.detection(new NDList(clsProbs.expandDims(0),
offsetPreds.expandDims(0),
anchors.expandDims(0))).head(); // shape = 1, 4, 6
output;
ND: (1, 4, 6) gpu(0) float32
[[[ 1. , 0.9 , 0.55 , 0.2 , 0.9 , 0.88 ],
[ 0. , 0.9 , 0.1 , 0.08 , 0.52 , 0.92 ],
[-1. , 0.8 , 0.08 , 0.2 , 0.56 , 0.95 ],
[-1. , 0.7 , 0.15 , 0.3 , 0.62 , 0.91 ],
],
]
We remove the prediction bounding boxes of category -1 and visualize the results retained by NMS.
Image img5 = img.duplicate();
for (int i = 0; i < output.size(1); i++) {
NDArray bbox = output.get(0, i);
// Skip prediction bounding boxes of category -1
if (bbox.getFloat(0) == -1) {
continue;
}
String[] labels = {"dog=", "cat="};
String className = labels[(int) bbox.getFloat(0)];
String prob = Float.toString(bbox.getFloat(1));
String label = className + prob;
drawBBoxes(img5, bbox.reshape(1, bbox.size()).get(new NDIndex(":, 2:")), new String[]{label});
}
img5.getWrappedImage()

In practice, we can remove prediction bounding boxes with lower confidence levels before performing NMS, thereby reducing the amount of computation for NMS. We can also filter the output of NMS, for example, by only retaining results with higher confidence levels as the final output.
13.2.5. Summary¶
We generate multiple anchor boxes with different sizes and aspect ratios, centered on each pixel.
IoU, also called Jaccard index, measures the similarity of two bounding boxes. It is the ratio of the intersecting area to the union area of two bounding boxes.
In the training set, we mark two types of labels for each anchor box: one is the category of the target contained in the anchor box and the other is the offset of the ground-truth bounding box relative to the anchor box.
When predicting, we can use non-maximum suppression (NMS) to remove similar prediction bounding boxes, thereby simplifying the results.
13.2.6. Exercises¶
Change the
sizesandratiosvalues in theMultiBoxPriorobject and observe the changes to the generated anchor boxes.Construct two bounding boxes with and IoU of 0.5, and observe their coincidence.
Verify the output of offset
labels.get(0)by marking the anchor box offsets as defined in this section (the constant is the default value).Modify the variable
anchorsin the “Labeling Training Set Anchor Boxes” and “Output Bounding Boxes for Prediction” sections. How do the results change?