Run this notebook online:![]() or Colab:
or Colab: ![]()
6.6. 卷积神经网络(LeNet)¶
我们现在拥有组装所需的所有原料 一个全功能的卷积神经网络。 在我们第一次接触图像数据时, 我们应用了多层感知器 (Section 4.2) 到时装MNIST数据集中的服装图片。 为了使这些数据适用于多层感知器, 我们首先从 \(28\times28\) 矩阵中展平每个图像 变成一个固定长度的 \(784\)-维向量, 然后用完全连接的层处理它们。 现在我们已经掌握了卷积层, 我们可以在图像中保留空间结构。 用卷积层代替密集层的另一个好处是, 我们将享受更简约的模型(需要的参数要少得多)。
在本节中,我们将介绍LeNet, 在最早发表的卷积神经网络中 因其在计算机视觉任务中的表现而引起广泛关注。 该模型由Yann Lecun介绍(并以其命名), 后来,美国电话电报公司贝尔实验室的一名研究员, 为了识别图像中的手写数字 LeNet5。 这部作品代表了顶峰 这项技术已经进行了十年的研究。 1989年,乐村发表了第一篇成功的研究论文 通过反向传播训练卷积神经网络。
当时LeNet取得了优异的成绩 匹配支持向量机(SVMs)的性能, 然后是监督学习中占主导地位的方法。 LeNet特最终适应了识别数字 自动取款机上的存款。 时至今日,一些自动取款机仍在运行该代码 Yann和他的同事Leon Bottou在20世纪90年代写的!
6.6.1. LeNet¶
从高层次上讲,LeNet由三部分组成: (i) 由两个卷积层组成的卷积编码器;和 (ii) 由三个完全相连的层组成的致密块体; 架构总结如下 Fig. 6.6.1.

Fig. 6.6.1 Data flow in LeNet 5. The input is a handwritten digit, the output a probability over 10 possible outcomes.¶
每个卷积块中的基本单位 是一个卷积层,一个S形激活函数, 以及随后的平均池操作。 请注意,虽然ReLUs和max-pooling工作得更好, 这些发现在90年代还没有被发现。 每个卷积层使用 \(5\times 5\) 的内核 还有一个S形激活函数。 这些层映射空间排列的输入 到多个二维要素地图,通常 增加频道的数量。 第一卷积层有6个输出通道, 而第二个有16个。 每个 \(2\times2\) 池操作(步骤2) 通过空间下采样将维度降低了\(4\)。 卷积块发出的输出大小如下所示: (批次大小、通道、高度、宽度)。
为了传递卷积块的输出 到完全连接的块, 我们必须把小批量中的每一个例子都展平。 换句话说,我们接受这个4D输入并转换它 进入完全连接层所需的二维输入: 作为提醒,我们想要的2D表现 使用第一个维度索引minibatch中的示例 第二步给出每个例子的平面向量表示。 LeNet’s的全连接层块有三个全连接层, 分别有120、84和10个输出。 因为我们还在进行分类, 10维输出层对应 到可能的输出类的数量。
在你真正理解的时候 LeNet内部发生的事情可能需要一些努力,
希望下面的代码片段能说服您 在现代深度学习图书馆中实施这样的模式
非常简单。 我们只需要实例化一个 Sequential 块
并将适当的层连接在一起。
%load ../utils/djl-imports
%load ../utils/plot-utils
import ai.djl.basicdataset.cv.classification.*;
import ai.djl.metric.*;
import org.apache.commons.lang3.ArrayUtils;
Engine.getInstance().setRandomSeed(1111);
NDManager manager = NDManager.newBaseManager();
SequentialBlock block = new SequentialBlock();
block
.add(Conv2d.builder()
.setKernelShape(new Shape(5, 5))
.optPadding(new Shape(2, 2))
.optBias(false)
.setFilters(6)
.build())
.add(Activation::sigmoid)
.add(Pool.avgPool2dBlock(new Shape(5, 5), new Shape(2, 2), new Shape(2, 2)))
.add(Conv2d.builder()
.setKernelShape(new Shape(5, 5))
.setFilters(16).build())
.add(Activation::sigmoid)
.add(Pool.avgPool2dBlock(new Shape(5, 5), new Shape(2, 2), new Shape(2, 2)))
// Blocks.batchFlattenBlock() 将转换形状的输入(批次大小、通道、高度、宽度)
// 输入形状(批量大小,通道*高度*宽度)
.add(Blocks.batchFlattenBlock())
.add(Linear
.builder()
.setUnits(120)
.build())
.add(Activation::sigmoid)
.add(Linear
.builder()
.setUnits(84)
.build())
.add(Activation::sigmoid)
.add(Linear
.builder()
.setUnits(10)
.build());
SequentialBlock {
Conv2d
LambdaBlock
avgPool2d
Conv2d
LambdaBlock
avgPool2d
batchFlatten
Linear
LambdaBlock
Linear
LambdaBlock
Linear
}
我们对最初的模型有点随意, 去除最后一层中的高斯激活。 除此之外,这个网络匹配 最初的LeNet5架构。我们还创建了模型和 Trainer对象,以便我们初始化结构一次。
通过单个通道(黑和白) \(28 \times 28\) 的网络图像
并在每一层打印输出形状, 我们可以检查模型以确保 它的行为符合
我们期待的是:numref:img_lenet_vert
float lr = 0.9f;
Model model = Model.newInstance("cnn");
model.setBlock(block);
Loss loss = Loss.softmaxCrossEntropyLoss();
Tracker lrt = Tracker.fixed(lr);
Optimizer sgd = Optimizer.sgd().setLearningRateTracker(lrt).build();
DefaultTrainingConfig config = new DefaultTrainingConfig(loss).optOptimizer(sgd) // 优化器(损失函数)
.optDevices(Engine.getInstance().getDevices(1)) // 单个GPU
.addEvaluator(new Accuracy()) // 模型精度
.addTrainingListeners(TrainingListener.Defaults.basic());
Trainer trainer = model.newTrainer(config);
NDArray X = manager.randomUniform(0f, 1.0f, new Shape(1, 1, 28, 28));
trainer.initialize(X.getShape());
Shape currentShape = X.getShape();
for (int i = 0; i < block.getChildren().size(); i++) {
Shape[] newShape = block.getChildren().get(i).getValue().getOutputShapes(new Shape[]{currentShape});
currentShape = newShape[0];
System.out.println(block.getChildren().get(i).getKey() + " layer output : " + currentShape);
}
01Conv2d layer output : (1, 6, 28, 28)
02LambdaBlock layer output : (1, 6, 28, 28)
03LambdaBlock layer output : (1, 6, 14, 14)
04Conv2d layer output : (1, 16, 10, 10)
05LambdaBlock layer output : (1, 16, 10, 10)
06LambdaBlock layer output : (1, 16, 5, 5)
07LambdaBlock layer output : (1, 400)
08Linear layer output : (1, 120)
09LambdaBlock layer output : (1, 120)
10Linear layer output : (1, 84)
11LambdaBlock layer output : (1, 84)
12Linear layer output : (1, 10)
请注意,表示的高度和宽度 在整个卷积块的每一层 减少(与上一层相比)。 第一个卷积层使用 \(2\) 像素的填充 以补偿高度和宽度的减少 否则,使用 \(5 \times 5\) 会导致这种情况。 相比之下,第二个卷积层放弃了填充, 因此,高度和宽度都减少了 \(4\) 像素。 当我们沿着一层层往上爬, 通道的数量逐层增加 从输入中的1到第一个卷积层后的6 第二层之后是16层。 然而,每个池层的高度和宽度减半。 最后,每个完全连接的层降低了维度, 最终发出一个输出,其维数 匹配类的数量。

Fig. 6.6.2 Compressed notation for LeNet5¶
6.6.2. 数据采集和训练¶
既然我们已经实现了这个模型, 让我们做一个实验,看看LeNet在时尚界的表现如何。
int batchSize = 256;
int numEpochs = Integer.getInteger("MAX_EPOCH", 10);
double[] trainLoss;
double[] testAccuracy;
double[] epochCount;
double[] trainAccuracy;
epochCount = new double[numEpochs];
for (int i = 0; i < epochCount.length; i++) {
epochCount[i] = (i + 1);
}
FashionMnist trainIter = FashionMnist.builder()
.optUsage(Dataset.Usage.TRAIN)
.setSampling(batchSize, true)
.optLimit(Long.getLong("DATASET_LIMIT", Long.MAX_VALUE))
.build();
FashionMnist testIter = FashionMnist.builder()
.optUsage(Dataset.Usage.TEST)
.setSampling(batchSize, true)
.optLimit(Long.getLong("DATASET_LIMIT", Long.MAX_VALUE))
.build();
trainIter.prepare();
testIter.prepare();
虽然卷积网络的参数很少, 它们的计算成本可能还会更高 比类似的深层多层感知器 因为每个参数都参与了更多的工作 乘法。 如果你可以访问GPU,这可能是一个好时机 把它付诸行动,加快训练。
训练函数 trainingChapter6 也类似 至 Section 3.6
中定义的 trainChapter3 。 因为我们将实现多层次的网络
今后,我们将主要依靠DJL。 以下列车功能采用DJL模型
作为输入,并进行相应的优化。 我们初始化模型参数
在块上使用Xavier初始值设定项。 就像MLP一样,我们的损失函数是交叉熵,
我们通过小批量随机梯度下降来最小化它。
public void trainingChapter6(ArrayDataset trainIter, ArrayDataset testIter,
int numEpochs, Trainer trainer) throws IOException, TranslateException {
double avgTrainTimePerEpoch = 0;
Map<String, double[]> evaluatorMetrics = new HashMap<>();
trainer.setMetrics(new Metrics());
EasyTrain.fit(trainer, numEpochs, trainIter, testIter);
Metrics metrics = trainer.getMetrics();
trainer.getEvaluators().stream()
.forEach(evaluator -> {
evaluatorMetrics.put("train_epoch_" + evaluator.getName(), metrics.getMetric("train_epoch_" + evaluator.getName()).stream()
.mapToDouble(x -> x.getValue().doubleValue()).toArray());
evaluatorMetrics.put("validate_epoch_" + evaluator.getName(), metrics.getMetric("validate_epoch_" + evaluator.getName()).stream()
.mapToDouble(x -> x.getValue().doubleValue()).toArray());
});
avgTrainTimePerEpoch = metrics.mean("epoch");
trainLoss = evaluatorMetrics.get("train_epoch_SoftmaxCrossEntropyLoss");
trainAccuracy = evaluatorMetrics.get("train_epoch_Accuracy");
testAccuracy = evaluatorMetrics.get("validate_epoch_Accuracy");
System.out.printf("loss %.3f," , trainLoss[numEpochs-1]);
System.out.printf(" train acc %.3f," , trainAccuracy[numEpochs-1]);
System.out.printf(" test acc %.3f\n" , testAccuracy[numEpochs-1]);
System.out.printf("%.1f examples/sec \n", trainIter.size() / (avgTrainTimePerEpoch / Math.pow(10, 9)));
}
现在让我们来训练这个模型。
trainingChapter6(trainIter, testIter, numEpochs, trainer);
loss 0.586, train acc 0.774, test acc 0.750
25027.0 examples/sec
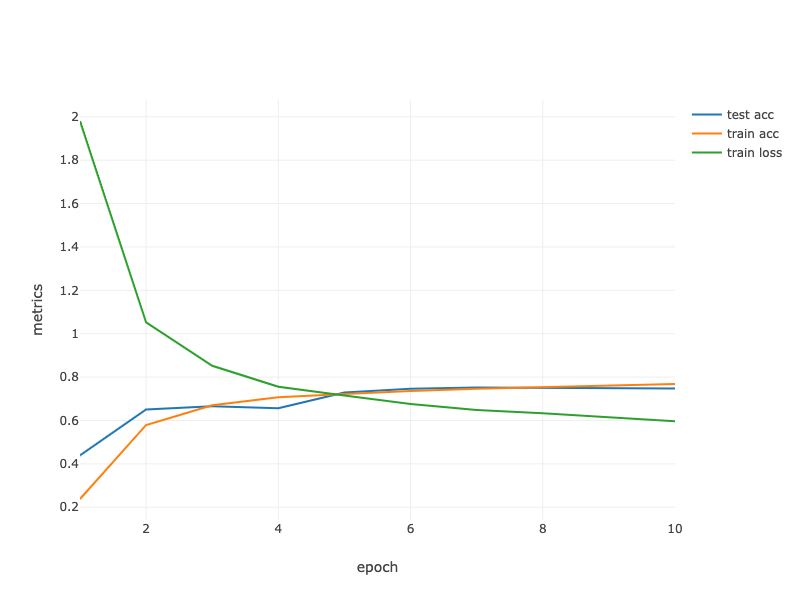
Fig. 6.6.3 Contour Gradient Descent.¶
String[] lossLabel = new String[trainLoss.length + testAccuracy.length + trainAccuracy.length];
Arrays.fill(lossLabel, 0, trainLoss.length, "train loss");
Arrays.fill(lossLabel, trainAccuracy.length, trainLoss.length + trainAccuracy.length, "train acc");
Arrays.fill(lossLabel, trainLoss.length + trainAccuracy.length,
trainLoss.length + testAccuracy.length + trainAccuracy.length, "test acc");
Table data = Table.create("Data").addColumns(
DoubleColumn.create("epoch", ArrayUtils.addAll(epochCount, ArrayUtils.addAll(epochCount, epochCount))),
DoubleColumn.create("metrics", ArrayUtils.addAll(trainLoss, ArrayUtils.addAll(trainAccuracy, testAccuracy))),
StringColumn.create("lossLabel", lossLabel)
);
render(LinePlot.create("", data, "epoch", "metrics", "lossLabel"), "text/html");
6.6.3. 总结¶
ConvNet是一种采用卷积层的网络。
在ConvNet中,我们交错卷积、非线性和(通常)池操作。
这些卷积块通常被布置成在增加通道数量的同时逐渐降低表示的空间分辨率。
在传统的convnet中,由卷积块编码的表示在发射输出之前由一个(或多个)密集层处理。
LeNet可以说是第一个成功部署此类网络的。
6.6.4. 练习¶
将平均池替换为最大池。会发生什么?
尝试基于LeNet构建更复杂的网络,以提高其精度。
调整卷积窗口的大小。
调整输出通道的数量。
调整激活功能(ReLU?)。
调整卷积层数。
调整完全连接的层的数量。
调整学习率和其他培训细节(初始化、历次等)
在原始MNIST数据集上尝试改进的网络。
显示第一层和第二层LeNet对不同输入(例如毛衣、外套)的激活情况。