Run this notebook online:![]() or Colab:
or Colab: ![]()
7.7. Densely Connected Networks (DenseNet)¶
ResNet significantly changed the view of how to parametrize the functions in deep networks. DenseNet is to some extent the logical extension of this. To understand how to arrive at it, let us take a small detour to theory. Recall the Taylor expansion for functions. For scalars it can be written as
7.7.1. Function Decomposition¶
The key point is that it decomposes the function into increasingly higher order terms. In a similar vein, ResNet decomposes functions into
That is, ResNet decomposes \(f\) into a simple linear term and a more complex nonlinear one. What if we want to go beyond two terms? A solution was proposed by [Huang et al., 2017] in the form of DenseNet, an architecture that reported record performance on the ImageNet dataset.

Fig. 7.7.1 The main difference between ResNet (left) and DenseNet (right) in cross-layer connections: use of addition and use of concatenation.¶
As shown in Fig. 7.7.1, the key difference between ResNet and DenseNet is that in the latter case outputs are concatenated rather than added. As a result we perform a mapping from \(\mathbf{x}\) to its values after applying an increasingly complex sequence of functions.
In the end, all these functions are combined in an MLP to reduce the number of features again. In terms of implementation this is quite simple—rather than adding terms, we concatenate them. The name DenseNet arises from the fact that the dependency graph between variables becomes quite dense. The last layer of such a chain is densely connected to all previous layers. The main components that compose a DenseNet are dense blocks and transition layers. The former defines how the inputs and outputs are concatenated, while the latter controls the number of channels so that it is not too large. The dense connections are shown in Fig. 7.7.2.

Fig. 7.7.2 Dense connections in DenseNet¶
7.7.2. Dense Blocks¶
DenseNet uses the modified “batch normalization, activation, and
convolution” architecture of ResNet (see the exercise in
Section 7.6). First, we implement this architecture in the
conv_block function.
%load ../utils/djl-imports
%load ../utils/plot-utils
%load ../utils/Training.java
%load ../utils/Accumulator.java
import ai.djl.basicdataset.cv.classification.*;
import ai.djl.metric.*;
import org.apache.commons.lang3.ArrayUtils;
public SequentialBlock convBlock(int numChannels) {
SequentialBlock block = new SequentialBlock()
.add(BatchNorm.builder().build())
.add(Activation::relu)
.add(Conv2d.builder()
.setFilters(numChannels)
.setKernelShape(new Shape(3, 3))
.optPadding(new Shape(1, 1))
.optStride(new Shape(1, 1))
.build()
);
return block;
}
A dense block consists of multiple convBlock units, each using the
same number of output channels. In the forward computation, however, we
concatenate the input and output of each block on the channel dimension.
class DenseBlock extends AbstractBlock {
private static final byte VERSION = 1;
public SequentialBlock net = new SequentialBlock();
public DenseBlock(int numConvs, int numChannels) {
super(VERSION);
for (int i = 0; i < numConvs; i++) {
net.add(addChildBlock("denseBlock" + i, convBlock(numChannels)));
}
}
@Override
public String toString() {
return "DenseBlock()";
}
@Override
protected NDList forwardInternal(
ParameterStore parameterStore,
NDList X,
boolean training,
PairList<String, Object> params) {
NDArray Y;
for (Block block : net.getChildren().values()) {
Y = block.forward(parameterStore, X, training).singletonOrThrow();
X = new NDList(NDArrays.concat(new NDList(X.singletonOrThrow(), Y), 1));
}
return X;
}
@Override
public Shape[] getOutputShapes(Shape[] inputs) {
Shape[] shapesX = inputs;
for (Block block : net.getChildren().values()) {
Shape[] shapesY = block.getOutputShapes(shapesX);
shapesX[0] = new Shape(
shapesX[0].get(0),
shapesY[0].get(1) + shapesX[0].get(1),
shapesX[0].get(2),
shapesX[0].get(3)
);
}
return shapesX;
}
@Override
protected void initializeChildBlocks(NDManager manager, DataType dataType, Shape... inputShapes) {
Shape shapesX = inputShapes[0];
for (Block block : this.net.getChildren().values()) {
block.initialize(manager, DataType.FLOAT32, shapesX);
Shape[] shapesY = block.getOutputShapes(new Shape[] {shapesX});
shapesX = new Shape(
shapesX.get(0),
shapesY[0].get(1) + shapesX.get(1),
shapesX.get(2),
shapesX.get(3)
);
}
}
}
In the following example, we define a convolution block (DenseBlock)
with two blocks of 10 output channels. When using an input with 3
channels, we will get an output with the \(3+2\times 10=23\)
channels. The number of convolution block channels controls the increase
in the number of output channels relative to the number of input
channels. This is also referred to as the growth rate.
NDManager manager = NDManager.newBaseManager();
SequentialBlock block = new SequentialBlock().add(new DenseBlock(2, 10));
NDArray X = manager.randomUniform(0f, 1.0f, new Shape(4, 3, 8, 8));
block.initialize(manager, DataType.FLOAT32, X.getShape());
ParameterStore parameterStore = new ParameterStore(manager, true);
Shape[] currentShape = new Shape[] {X.getShape()};
for (Block child : block.getChildren().values()) {
currentShape = child.getOutputShapes(currentShape);
}
currentShape[0]
(4, 23, 8, 8)
7.7.3. Transition Layers¶
Since each dense block will increase the number of channels, adding too many of them will lead to an excessively complex model. A transition layer is used to control the complexity of the model. It reduces the number of channels by using the \(1\times 1\) convolutional layer and halves the height and width of the average pooling layer with a stride of 2, further reducing the complexity of the model.
public SequentialBlock transitionBlock(int numChannels) {
SequentialBlock blk = new SequentialBlock()
.add(BatchNorm.builder().build())
.add(Activation::relu)
.add(Conv2d.builder()
.setFilters(numChannels)
.setKernelShape(new Shape(1, 1))
.optStride(new Shape(1, 1))
.build()
)
.add(Pool.avgPool2dBlock(new Shape(2, 2), new Shape(2, 2)));
return blk;
}
Apply a transition layer with 10 channels to the output of the dense block in the previous example. This reduces the number of output channels to 10, and halves the height and width.
block = transitionBlock(10);
block.initialize(manager, DataType.FLOAT32, currentShape);
for (Pair<String, Block> pair: block.getChildren()) {
currentShape = pair.getValue().getOutputShapes(currentShape);
}
currentShape[0]
(4, 10, 4, 4)
7.7.4. DenseNet Model¶
Next, we will construct a DenseNet model. DenseNet first uses the same single convolutional layer and maximum pooling layer as ResNet.
SequentialBlock net = new SequentialBlock()
.add(Conv2d.builder()
.setFilters(64)
.setKernelShape(new Shape(7, 7))
.optStride(new Shape(2, 2))
.optPadding(new Shape(3, 3))
.build())
.add(BatchNorm.builder().build())
.add(Activation::relu)
.add(Pool.maxPool2dBlock(new Shape(3, 3), new Shape(2, 2), new Shape(1, 1)));
Then, similar to the four residual blocks that ResNet uses, DenseNet uses four dense blocks. Similar to ResNet, we can set the number of convolutional layers used in each dense block. Here, we set it to 4, consistent with the ResNet-18 in the previous section. Furthermore, we set the number of channels (i.e., growth rate) for the convolutional layers in the dense block to 32, so 128 channels will be added to each dense block.
In ResNet, the height and width are reduced between each module by a residual block with a stride of 2. Here, we use the transition layer to halve the height and width and halve the number of channels.
int numChannels = 64;
int growthRate = 32;
int[] numConvsInDenseBlocks = new int[]{4, 4, 4, 4};
for (int index = 0; index < numConvsInDenseBlocks.length; index++) {
int numConvs = numConvsInDenseBlocks[index];
net.add(new DenseBlock(numConvs, growthRate));
numChannels += (numConvs * growthRate);
if (index != (numConvsInDenseBlocks.length - 1)) {
numChannels = (numChannels / 2);
net.add(transitionBlock(numChannels));
}
}
Similar to ResNet, a global pooling layer and fully connected layer are connected at the end to produce the output.
net
.add(BatchNorm.builder().build())
.add(Activation::relu)
.add(Pool.globalAvgPool2dBlock())
.add(Linear.builder().setUnits(10).build());
SequentialBlock {
Conv2d
BatchNorm
LambdaBlock
maxPool2d
DenseBlock {
denseBlock0 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock1 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock2 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock3 {
BatchNorm
LambdaBlock
Conv2d
}
}
SequentialBlock {
BatchNorm
LambdaBlock
Conv2d
avgPool2d
}
DenseBlock {
denseBlock0 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock1 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock2 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock3 {
BatchNorm
LambdaBlock
Conv2d
}
}
SequentialBlock {
BatchNorm
LambdaBlock
Conv2d
avgPool2d
}
DenseBlock {
denseBlock0 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock1 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock2 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock3 {
BatchNorm
LambdaBlock
Conv2d
}
}
SequentialBlock {
BatchNorm
LambdaBlock
Conv2d
avgPool2d
}
DenseBlock {
denseBlock0 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock1 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock2 {
BatchNorm
LambdaBlock
Conv2d
}
denseBlock3 {
BatchNorm
LambdaBlock
Conv2d
}
}
BatchNorm
LambdaBlock
globalAvgPool2d
Linear
}
7.7.5. Data Acquisition and Training¶
Since we are using a deeper network here, in this section, we will reduce the input height and width from 224 to 96 to simplify the computation.
int batchSize = 256;
float lr = 0.1f;
int numEpochs = Integer.getInteger("MAX_EPOCH", 10);
double[] trainLoss;
double[] testAccuracy;
double[] epochCount;
double[] trainAccuracy;
epochCount = new double[numEpochs];
for (int i = 0; i < epochCount.length; i++) {
epochCount[i] = (i + 1);
}
FashionMnist trainIter = FashionMnist.builder()
.addTransform(new Resize(96))
.addTransform(new ToTensor())
.optUsage(Dataset.Usage.TRAIN)
.setSampling(batchSize, true)
.optLimit(Long.getLong("DATASET_LIMIT", Long.MAX_VALUE))
.build();
FashionMnist testIter = FashionMnist.builder()
.addTransform(new Resize(96))
.addTransform(new ToTensor())
.optUsage(Dataset.Usage.TEST)
.setSampling(batchSize, true)
.optLimit(Long.getLong("DATASET_LIMIT", Long.MAX_VALUE))
.build();
trainIter.prepare();
testIter.prepare();
Model model = Model.newInstance("cnn");
model.setBlock(net);
Loss loss = Loss.softmaxCrossEntropyLoss();
Tracker lrt = Tracker.fixed(lr);
Optimizer sgd = Optimizer.sgd().setLearningRateTracker(lrt).build();
DefaultTrainingConfig config = new DefaultTrainingConfig(loss).optOptimizer(sgd) // Optimizer (loss function)
.addEvaluator(new Accuracy()) // Model Accuracy
.addTrainingListeners(TrainingListener.Defaults.logging()); // Logging
Trainer trainer = model.newTrainer(config);
trainer.initialize(new Shape(1, 1, 96, 96));
Map<String, double[]> evaluatorMetrics = new HashMap<>();
double avgTrainTimePerEpoch = Training.trainingChapter6(trainIter, testIter, numEpochs, trainer, evaluatorMetrics);
INFO Training on: 4 GPUs.
INFO Load MXNet Engine Version 1.9.0 in 0.075 ms.
Training: 100% |████████████████████████████████████████| Accuracy: 0.81, SoftmaxCrossEntropyLoss: 0.52
Validating: 100% |████████████████████████████████████████|
INFO Epoch 1 finished.
INFO Train: Accuracy: 0.81, SoftmaxCrossEntropyLoss: 0.52
INFO Validate: Accuracy: 0.69, SoftmaxCrossEntropyLoss: 0.96
Training: 100% |████████████████████████████████████████| Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.30
Validating: 100% |████████████████████████████████████████|
INFO Epoch 2 finished.
INFO Train: Accuracy: 0.89, SoftmaxCrossEntropyLoss: 0.30
INFO Validate: Accuracy: 0.85, SoftmaxCrossEntropyLoss: 0.41
Training: 100% |████████████████████████████████████████| Accuracy: 0.91, SoftmaxCrossEntropyLoss: 0.25
Validating: 100% |████████████████████████████████████████|
INFO Epoch 3 finished.
INFO Train: Accuracy: 0.91, SoftmaxCrossEntropyLoss: 0.25
INFO Validate: Accuracy: 0.77, SoftmaxCrossEntropyLoss: 0.62
Training: 100% |████████████████████████████████████████| Accuracy: 0.92, SoftmaxCrossEntropyLoss: 0.22
Validating: 100% |████████████████████████████████████████|
INFO Epoch 4 finished.
INFO Train: Accuracy: 0.92, SoftmaxCrossEntropyLoss: 0.22
INFO Validate: Accuracy: 0.87, SoftmaxCrossEntropyLoss: 0.34
Training: 100% |████████████████████████████████████████| Accuracy: 0.93, SoftmaxCrossEntropyLoss: 0.20
Validating: 100% |████████████████████████████████████████|
INFO Epoch 5 finished.
INFO Train: Accuracy: 0.93, SoftmaxCrossEntropyLoss: 0.20
INFO Validate: Accuracy: 0.85, SoftmaxCrossEntropyLoss: 0.42
Training: 100% |████████████████████████████████████████| Accuracy: 0.93, SoftmaxCrossEntropyLoss: 0.18
Validating: 100% |████████████████████████████████████████|
INFO Epoch 6 finished.
INFO Train: Accuracy: 0.93, SoftmaxCrossEntropyLoss: 0.18
INFO Validate: Accuracy: 0.86, SoftmaxCrossEntropyLoss: 0.40
Training: 100% |████████████████████████████████████████| Accuracy: 0.94, SoftmaxCrossEntropyLoss: 0.17
Validating: 100% |████████████████████████████████████████|
INFO Epoch 7 finished.
INFO Train: Accuracy: 0.94, SoftmaxCrossEntropyLoss: 0.17
INFO Validate: Accuracy: 0.84, SoftmaxCrossEntropyLoss: 0.43
Training: 100% |████████████████████████████████████████| Accuracy: 0.94, SoftmaxCrossEntropyLoss: 0.15
Validating: 100% |████████████████████████████████████████|
INFO Epoch 8 finished.
INFO Train: Accuracy: 0.94, SoftmaxCrossEntropyLoss: 0.15
INFO Validate: Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.30
Training: 100% |████████████████████████████████████████| Accuracy: 0.95, SoftmaxCrossEntropyLoss: 0.14
Validating: 100% |████████████████████████████████████████|
INFO Epoch 9 finished.
INFO Train: Accuracy: 0.95, SoftmaxCrossEntropyLoss: 0.14
INFO Validate: Accuracy: 0.90, SoftmaxCrossEntropyLoss: 0.29
Training: 100% |████████████████████████████████████████| Accuracy: 0.95, SoftmaxCrossEntropyLoss: 0.13
Validating: 100% |████████████████████████████████████████|
INFO Epoch 10 finished.
INFO Train: Accuracy: 0.95, SoftmaxCrossEntropyLoss: 0.13
INFO Validate: Accuracy: 0.92, SoftmaxCrossEntropyLoss: 0.25
trainLoss = evaluatorMetrics.get("train_epoch_SoftmaxCrossEntropyLoss");
trainAccuracy = evaluatorMetrics.get("train_epoch_Accuracy");
testAccuracy = evaluatorMetrics.get("validate_epoch_Accuracy");
System.out.printf("loss %.3f,", trainLoss[numEpochs - 1]);
System.out.printf(" train acc %.3f,", trainAccuracy[numEpochs - 1]);
System.out.printf(" test acc %.3f\n", testAccuracy[numEpochs - 1]);
System.out.printf("%.1f examples/sec", trainIter.size() / (avgTrainTimePerEpoch / Math.pow(10, 9)));
System.out.println();
loss 0.131, train acc 0.951, test acc 0.915
2423.0 examples/sec
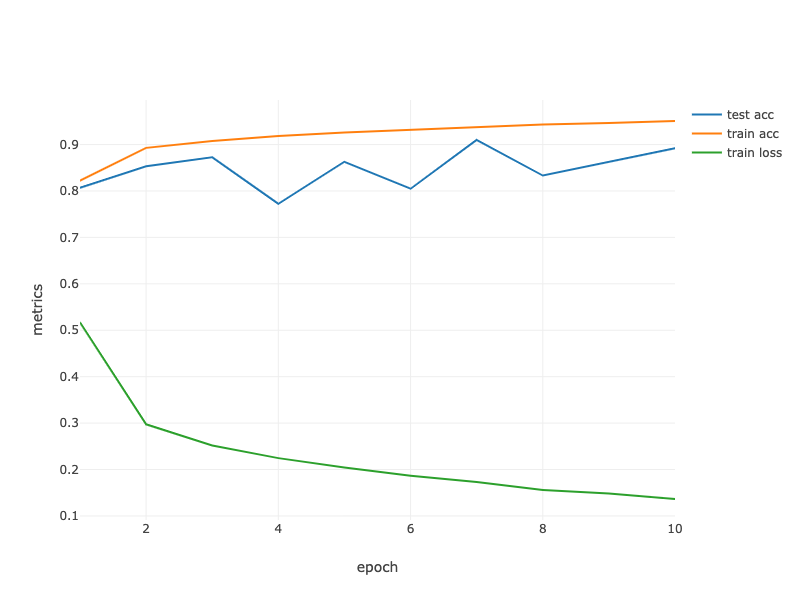
Fig. 7.7.3 Contour Gradient Descent.¶
String[] lossLabel = new String[trainLoss.length + testAccuracy.length + trainAccuracy.length];
Arrays.fill(lossLabel, 0, trainLoss.length, "train loss");
Arrays.fill(lossLabel, trainAccuracy.length, trainLoss.length + trainAccuracy.length, "train acc");
Arrays.fill(lossLabel, trainLoss.length + trainAccuracy.length,
trainLoss.length + testAccuracy.length + trainAccuracy.length, "test acc");
Table data = Table.create("Data").addColumns(
DoubleColumn.create("epoch", ArrayUtils.addAll(epochCount, ArrayUtils.addAll(epochCount, epochCount))),
DoubleColumn.create("metrics", ArrayUtils.addAll(trainLoss, ArrayUtils.addAll(trainAccuracy, testAccuracy))),
StringColumn.create("lossLabel", lossLabel)
);
render(LinePlot.create("", data, "epoch", "metrics", "lossLabel"),"text/html");
7.7.6. Summary¶
In terms of cross-layer connections, unlike ResNet, where inputs and outputs are added together, DenseNet concatenates inputs and outputs on the channel dimension.
The main units that compose DenseNet are dense blocks and transition layers.
We need to keep the dimensionality under control when composing the network by adding transition layers that shrink the number of channels again.
7.7.7. Exercises¶
Why do we use average pooling rather than max-pooling in the transition layer?
One of the advantages mentioned in the DenseNet paper is that its model parameters are smaller than those of ResNet. Why is this the case?
One problem for which DenseNet has been criticized is its high memory consumption.
Is this really the case? Try to change the input shape to \(224\times 224\) to see the actual (GPU) memory consumption.
Can you think of an alternative means of reducing the memory consumption? How would you need to change the framework?
Implement the various DenseNet versions presented in Table 1 of [Huang et al., 2017].
Why do we not need to concatenate terms if we are just interested in \(\mathbf{x}\) and \(f(\mathbf{x})\) for ResNet? Why do we need this for more than two layers in DenseNet?
Design a DenseNet for fully connected networks and apply it to the Housing Price prediction task.